Genome Diaries
-
- from Shaastra :: vol 04 issue 08 :: Sep 2025

Twenty-five years after the human genome was drafted, research in India is yielding life-saving results.
Sometime in 2015, a couple expecting a child visited Anju Shukla's clinic at the Department of Medical Genetics in Kasturba Medical College (KMC), Manipal. The couple was worried. Their two elder children were doing well, but they had lost two others in early childhood. They had visited many doctors, done the rounds with their children, and yet a clear diagnosis had eluded them. They wanted to understand the fate of the child yet to be born.
Even though a decade has passed, Shukla, now Professor and Head of the Department of Medical Genetics at KMC, remembers that day of consultation well. The couple had brought previous medical records of their deceased children. The toddlers had severe development problems: epilepsy, seizures, and off-the-chart biochemical parameters, especially lactate. MRI scans of the brain were also available and were strikingly different from regular scans; the brain appeared relatively smooth and showed numerous changes in the white matter. The MRI showed typical signs of pachygyria, a malformation of the cerebrum. But even with all these investigative reports, the exact cause behind the debilitating symptoms was not clear. There was no way of knowing whether the next child would be affected.
As a medical geneticist, Shukla's next step was to look at the DNA of the parents. The parents had also earlier done DNA testing for their deceased children. However, when sequenced and analysed, the DNA did not reveal anything significant. A breakthrough happened a year later, when Shukla's colleagues found imaging records of a young patient in their database whose brain scans were similar to those of the children from the earlier family.
There were two children in the second family, and both had died in early childhood. When the DNA sequences of the children from the two families were compared, both sets showed a mutation in the ISCA1 gene, which is essential for optimal mitochondrial activity. The mutation was significant enough to interfere with the gene's function. The affected children from both families had two copies of this mutation, received from each of the parents. When the DNA of the parents and healthy siblings in both families was examined, they were found to be carriers of the disease, because they each had only one copy of the damaged gene.
Geneticists refer to this pattern of inheritance as autosomal recessive, as the disease only expresses itself when the damaged gene is inherited from both parents. A simple DNA test in any individual, or even an embryo, can reveal the status of the gene and the likelihood of developing the disease, a type of multiple mitochondrial dysfunction syndrome.
In the decade that Shukla has spent at KMC, she has met with hundreds of families in similar situations: families that have no understanding of why a certain disease has a stranglehold over their family. In 2018, Shukla and colleagues published a paper in the American Journal of Medical Genetics (link to come), where they explained the reasons behind another rare disease characterised by symptoms of developmental delay, variably impaired intellectual development, behavioural abnormalities, and dysmorphic features. By analysing the DNA sequence of two patients at a genetics clinic in the U.S. and three at the KMC clinic, the researchers found that mutations in a gene called BCORL1 on the X chromosome were responsible for the disease. Later, the disease was named Shukla-Vernon syndrome (SHUVER) after the researchers who studied it.
Because such diseases are limited to families or small groups of people, they are often collectively referred to as rare diseases. Although rare, their collective burden is substantial. It is estimated that there are 70-100 million rare disease patients in India today (bit.ly/rare-diseases-India).
The collective burden of rare diseases is substantial. It is estimated that there are 70-100 million rare disease patients in India today.
Most rare diseases have a hereditary component, and information from DNA is vital for diagnosing these diseases. Not only does it pinpoint the cause of the disease, but it also helps the affected families figure out how to move forward with the disease. "Diagnosis is the first thing. Based on that, you are going to have a (disease) management protocol. You are going to know what you can expect for the child in the future. What will be the prognosis?" says Shukla. Without the DNA data, most rare diseases remain unsolved.
Work on rare diseases picked up after 2001, with access to data from the Human Genome Project, a multi-country research initiative. The baseline sequence of the human genome, made public through the project, has enabled researchers worldwide to study rare, inherited disorders with greater efficiency. "Twenty years back, I spent almost two and a half years along with a few of my colleagues to just decipher one gene, one mutation in a family," says V.L. Ramprasad, Chief Executive Officer of MedGenome, a Bengaluru-based genetic diagnostics company that routinely does DNA tests for rare diseases. "Today, in the lab where I am sitting, there are 200 people doing 1,000 such diseases in 1,000 such patients a day."
THE BIG PROJECT
Launched in October 1990, the Human Genome Project led to the first sequencing of the entire human genome — a sequence that reveals how the three billion letters of the DNA molecule are arranged in each cell of the body. The first draft of the sequence was released 25 years ago in 2001. The project cost $3 billion.
The DNA alphabet is made up of four letters: A, T, G, and C. Each of these letters represents a chemical called a nucleotide, with A standing for Adenine, T for Thymine, G for Guanine, and C for Cytosine. Every human shares the same genetic sequence. Only 0.1% of the DNA differs from one human being to another, but this difference is responsible for all the variations seen in the human population. The DNA changes that underlie this variation can be of different types: a change in the sequence of nucleotides, the replacement of one nucleotide with another, or the loss of nucleotides.

Access to the baseline genome sequence transformed how genetics research was conducted globally, making it possible for researchers to compare the DNA sequences of people from different ethnicities, with varying health statuses, and those affected by different diseases. It provided them with the tools to identify the DNA variations that underpinned these differences.
In 2001, when the first draft of the sequence was released, there was great optimism and hope worldwide that access to the DNA sequence of individuals would transform the diagnosis and treatment of diseases. Medical scientists believed that sequencing the DNA would lead to treatment strategies for every disease that existed. Time would show that there was no straight path from disease to treatment through the DNA sequence. Nonetheless, the Human Genome Project paved the way for unprecedented understanding and in-depth study of diseases.
NEW WAY OF DOING THINGS
When the draft was released, B.K. Thelma was leading a medical genetics and genomics laboratory at the University of Delhi, South Campus. The lab worked on many genetic diseases: those caused by a mutation in a single gene, as well as complex diseases such as Parkinson's and schizophrenia, caused by the interplay of genetic and environmental factors.

Before the project, it was challenging to identify the genetic basis of such complex diseases. Only a few genes involved in the biochemical pathways associated with the disease were known, and little was clear about variations in these genes. But after the release of the draft sequence, Thelma says, "we had tens of thousands of landmarks that we could kind of put our fingers on." The landmarks are the variations in the DNA sequence of genes associated with a disease. A common type of DNA variation that researchers study is single-nucleotide polymorphisms (SNPs), the change of one nucleotide at a specific location on the DNA strand.
SNPs (pronounced as Snips) are the most common type of variation in the DNA. They occur roughly once every 1,000 nucleotides on average, which means there are roughly 4-5 million SNPs in a person's genome. But not every variation in the DNA sequence can qualify as a genuine SNP. Only when a variation is found in at least 1% of the population can it be classified as an SNP. They are a valuable and widely used tool for exploring genes associated with disease. "We did not conquer the disease genomics with that (draft sequence), but what we got was a huge amount of single-nucleotide polymorphism information from across the genome," Thelma says.
People from diverse ethno-linguistic groups exhibit genetic differences. Researchers use SNPs to flag differences unique to a subgroup.
Just two years after the release of the draft genome data, Thelma secured a grant from the Department of Biotechnology to study SNPs in genes related to schizophrenia and Parkinson's disease. They were conducting association studies — trying to identify the SNP variants that are associated with the presence of the disease. The lab had already been working with the two diseases before 2001, and they had a large number of DNA samples from people with schizophrenia and Parkinson's. They began looking at all the SNPs in the genes relevant to the two diseases. "Instead of doing one or two SNPs in a thousand samples, we were doing hundreds of SNPs in thousands of samples," she says. "We simply leapfrogged in our association studies in complex diseases."
By 2008, they were working on more diseases, such as ulcerative colitis and rheumatoid arthritis, using the Human Genome Project data. They were now using a hypothesis-free approach called the Genome-Wide Association Study (GWAS). Instead of looking for SNPs in a select set of genes, they now searched for SNPs in the entire genome. Their analyses revealed seven genes associated with ulcerative colitis and one with rheumatoid arthritis in the Indian population. These genes were not seen in genome-wide studies done on the Western population. Lab studies showed that the gene for rheumatoid arthritis, ARL15, was a druggable target, Thelma says.
In human genetics labs across India, a similar script was unfolding, utilising genome data to use genomics in a new way. K. Thangaraj, Professor and J.C. Bose Fellow at the Centre for Cellular and Molecular Biology (CCMB), Hyderabad, who was studying the genetics of male infertility, employed the same genome-wide strategy to identify eight novel genes contributing to infertility in males in the Indian population. In addition to working on the genetics of cardiovascular diseases and mitochondrial disorders, his lab also studied the population history of Indians, using genetic tools.
INDIAN DNA: PAST AND PRESENT
India is one of the world's most genetically diverse regions, with more than 1.7 billion people and over 4,000 different ethno-linguistic groups. Just as cultural differences exist, people from diverse ethno-linguistic groups also exhibit genetic differences among them. Researchers study these differences using SNPs, identifying those that are unique to a population subgroup, and then use statistical tools to analyse patterns in the distribution of SNPs. Their work became deeper and easier after genome data became available.

Using SNPs and statistical tools, Thangaraj and his colleagues reported in Nature in 2009 (bit.ly/ANI-ASI-ancestry) that the present-day Indian population has descended from two distinct groups: Ancestral South Indians (ASI) and Ancestral North Indians (ANI). In another study published in 2013 in the American Journal of Human Genetics (bit.ly/AJHG-evidence), researchers found that approximately 1,900-4,200 years ago, there was intermingling between ANI and ASI, as well as within these groups. However, around 1,900 years ago, the ethno-linguistic groups started becoming more defined, intermingling stopped, and endogamy (the practice of marrying within the community) began to set in. This cultural practice ended up shaping the fabric of Indian DNA and giving it its unique features. While the Indian DNA is constituted with the diversity of ethno-linguistic groups, each group is an island in itself. There are traits, diseases, and other characteristics that are specific to certain groups. Also, there are features that make it distinct from the Western population.
Indian geneticists are now working on developing a baseline Indian genome sequence. Thangaraj is part of a multi-institute project called the Genome India Project, under which researchers have sequenced the DNA of 10,000 people from 83 subgroups and are using the data to create a baseline Indian DNA sequence.
Indian geneticists are working on developing a baseline Indian genome sequence. Researchers have sequenced the DNA of 10,000 people from 83 subgroups.
In a short communication published earlier in 2025 in Nature Genetics (bit.ly/genome-mapping), the Genome India Project researchers shared preliminary findings, reporting the presence of 130 million genetic variants in the tested population: many of these had not been captured in global studies. "The 83 different subgroup samples in the project have each got their own unique set of variations and some that they share with other subgroups," says Bratati Kahali, Associate Professor at the Centre for Brain Research, the Indian Institute of Science. "There is a very colourful matrix of sharing and uniqueness going on in these populations," says Kahali, who is also part of the Genome India Project. A detailed paper on the variations and their impact is expected later this year. Thangaraj says that the data from the project will "give us a lot of information about the origin of people, about our health, and the genetics responsible for differences in therapeutic response".
THERAPEUTICS AND GENOMIC DATA
SNPs or other changes in the DNA can have a big impact on how an individual metabolises a drug. Sometimes these differences can cause a drug to work in some people and not in others. There is an entire branch of science dedicated to studying these differences, called pharmacogenomics. In a 2025 review article (bit.ly/Model-Drugs), published in the Journal of Xenobiotics, researchers refer to genetic variants that impact the metabolism of drugs included in the World Health Organization (WHO) Model Lists of Essential Medicines. The researchers involved in the study highlighted 57 drugs with actionable pharmacogenomics relevant to India. These drugs impact a variety of conditions, including mental health (amitriptyline, carbamazepine, phenytoin), autoimmune diseases (azathioprine), and cancer (fluorouracil, mercaptopurine, nilotinib, methotrexate, rituximab, irinotecan).
Two common over-the-counter drugs — ibuprofen and omeprazole –– were also part of the list. Ibuprofen's metabolism in adults is influenced by variants in the CYP2C9 gene, whereas omeprazole, a molecule that blocks acid production in the stomach, exhibits varied metabolic responses based on genetic variants, primarily in the CYP2C19 gene. The genetic variants determine whether someone is a fast or a slow metaboliser of a drug. "If you metabolise something very fast, you'll not get the optimum outcome of that medicine," says Gayatri R. Iyer, one of the authors of the study and a scientist at the Tata Institute of Genetics and Society. "If you are a very poor metaboliser, the drug will keep accumulating in your system. There will be too much load on the liver, leading to toxicity in the body, and then you will see adverse reactions." According to Iyer, pre-emptive genetic testing for how a person is going to respond to drugs — at least some commonly used ones — will help.
For example, a cancer chemotherapy drug, 5-fluorouracil (5-FU), is metabolised in the body by the enzyme dihydropyrimidine dehydrogenase (DPYD). Genetic variants in the DPYD gene can cause partial or complete inactivity of this enzyme, leading to adverse reactions and, in some cases, even fatality. An August 2025 study (bit.ly/DPYD-gene) in the journal Pharmacogenomics by researchers from Karkinos Healthcare, a cancer care company in Mumbai, examined the prevalence of zero-function and low-function variants of the DPYD gene in Indians. In a cohort of 1,612 individuals, the researchers found that 5.3% carried an inactive or low-function DPYD variant. "These results support the urgency in implementing preemptive DPYD genotyping to avoid adverse drug reactions," write the researchers in the paper.
In another class of cancer drugs called PARP — Poly (ADP-ribose) polymerase — inhibitors, genetic testing can help determine if an appropriate target for the drug is present in the cancer. In some cancer cells, the DNA repair mechanism is impaired due to mutations in the genes responsible for DNA repair. These cancer cells rely on PARP to repair their DNA and keep growing. PARP inhibitors stop the cancer cell from repairing its damaged DNA and thereby prevent its proliferation. Ramprasad of MedGenome says that only about 50% people who have these cancers have the defective DNA repair pathway. "So you can use this drug only on 50% of them." He says that MedGenome has conducted this test in over 5,000 patients so far. Similarly, in lung cancer, a new treatment called Tyrosine Kinase Inhibitor therapy improves treatment outcomes in patients with a mutation in the epidermal growth factor receptor gene. "A simple TKI treatment will sometimes double, even triple, the overall survival and progression," says Ramprasad. According to him, oncology testing is the fastest-growing category at MedGenome. He stresses that the Human Genome Project has made the biggest impact on diagnostics and genetic testing in India.

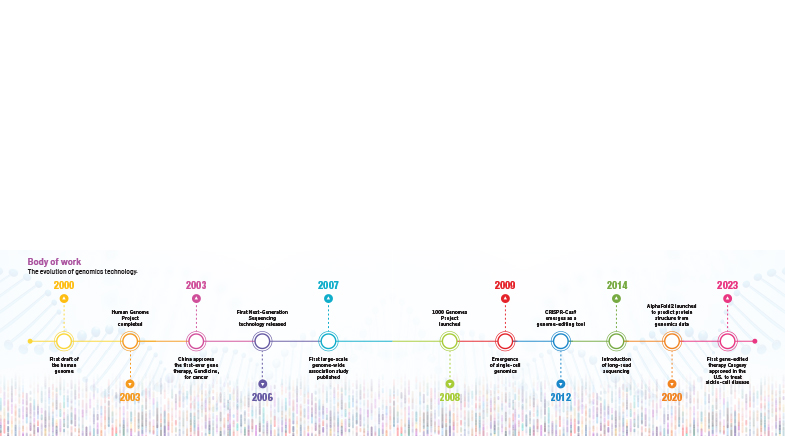
Such genetic tests would not have been possible without knowing the baseline sequence of the human genome. The first sequence was a trigger point for a cascade of changes. Part of the reason that made it possible was the rapid progress in technology and the tools researchers use to sequence DNA (see timeline: 'Body of work'). It cost billions of dollars to sequence the first genome, but as technology advanced, the cost came down rapidly. Today, it costs just about $100 to sequence a genome. The lowering of costs has resulted in increased availability and democratisation of the technology.
In December 2024, researchers at the Christian Medical College Vellore reported using gene therapy to treat haemophilia, a blood-clotting disorder.
With 25 years of progress after the first draft, gene therapies (that can correct the flaw in a gene) are now becoming a reality. In December 2024, researchers at the Christian Medical College Vellore reported using gene therapy to treat haemophilia, a blood-clotting disorder, in five patients. Haemophilia patients require blood transfusions nearly every week. However, patients who received gene therapy did not require transfusions over a 14-month-long follow-up period. In another example, at the Institute of Genomics and Integrative Biology (IGIB) in New Delhi, researchers are developing gene therapy for sickle cell anaemia, a genetic disease caused by mutations in haemoglobin genes, which reduces the blood's oxygen-carrying capacity. At Narayana Nethralaya in Bengaluru, researchers are developing gene therapy for eye diseases such as keratoconus and retinitis pigmentosa. Other researchers are looking at combining genomics data with datasets on protein and RNA and using AI/ML tools to harness information from these integrated datasets. "The secrets of the human genome are too vast to be uncovered fully," says Thelma. But researchers' familiarity with it has certainly grown, and they are closer than ever to achieving the goals envisioned 25 years ago.
See also:









Magnificent mangroves
Tech and innovation prop up mangroves in climate-proofing the future.


@: a symbol sets off an e-mail revolution
In 1971, the @ symbol was ‘rediscovered’ and elevated to a defining symbol of the computer age. Today, it ‘delivers’ over 300 billion e-mails a day!

A flood of ideas
Ready for a cot-cum-boat, crop-specific forecasts and stable bio-specimen storage?

Have a
story idea?
Tell us.
Do you have a recent research paper or an idea for a science/technology-themed article that you'd like to tell us about?
GET IN TOUCH