High Notes
-
- from Shaastra :: vol 03 issue 02 :: Mar 2024
How technology has enriched music — for both the creator and the connoisseur.
As a music aficionado, Shreyan Chowdhury had often wondered why the same composition played by different musicians felt so different. Bach's Prelude in C Major, for example, sounded staccato when played by the Canadian pianist Glenn Gould, with each note standing out distinctly. The Austrian pianist Friedrich Gulda, on the other hand, played it with one note merging into the next, making the music move smoothly without breaks. Gould's Bach sounded chaotic and aggressive; Gulda's flowed, and was relaxing. What made the emotional impact of the same piece so different?
Chowdhury grew up in a family of amateur musicians and connoisseurs of music. He started learning the guitar when he was 10 years old. His mother played the Hawaiian guitar. He had listened to a wide variety of music as a child. His grandparents owned a vinyl record player on which they often played the German band Kraftwerk, whose compositions had a profound influence on Chowdhury. Kraftwerk, a pioneer in electronic music in the 1970s, started a synthesiser boom that seemed to come from the future. Chowdhury had made a mental note when he listened to its electronic music album, The Man-Machine. He would return to it later in life.
Chowdhury studied electrical engineering at the Indian Institute of Technology (IIT) in Kanpur and went to the Johannes Kepler University Linz in Austria for a PhD. His supervisor there was Gerhard Widmer, a computer scientist and Head of the university's Institute of Computational Perception. Widmer was deeply interested in the underlying principles of musical emotion. Specifically, he sought to understand how different artistes produced varying effects of the same composition and yet managed to sound the same at another level. It was a complex problem that could be explored from different perspectives: musicology, psychology, cognitive sciences, computational sciences and so on. Being a computer scientist, Widmer chose to investigate it by building data models. If there were underlying principles behind musical emotion, he argued, a computer could spot them in the data and tell the scientists how to recreate the emotions.
Chowdhury had applied for a PhD at Linz when Widmer's work caught his attention. The two were soon working together as teacher and student. "As humans," Chowdhury says, "we are used to extracting emotion from the music we hear. Our aim is to have a computer do the same thing." His long-term goal is to develop computers that generate music with true emotion instead of pieces that sound robotic. Currently, computer-generated music does not sound human. One day — Widmer, Chowdhury and their colleagues hope — it will.
Shreyan Chowdhury's long-term goal is to develop computers that generate music with true emotion instead of pieces that sound robotic.
SOUND OF PRECISION
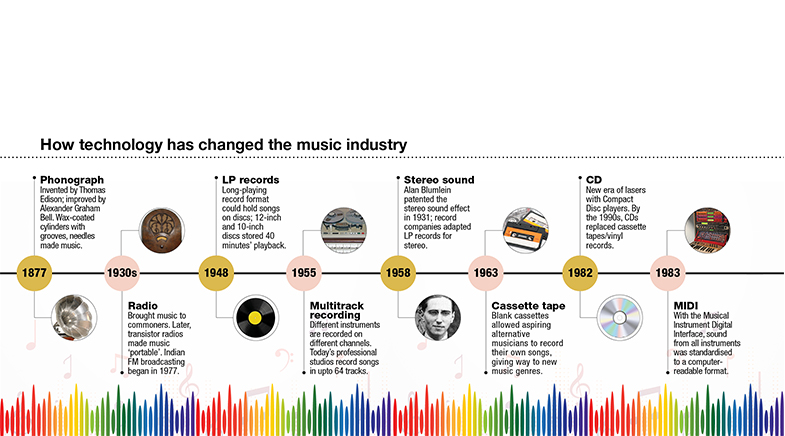
Music technology has had a long history with fuzzy boundaries. A musical instrument is a product of music technology. It is not invented fully formed but developed over centuries by skilled hands and sensitive ears, craftsmen and women who keep improving the instrument through continual tweaking. The piano, for instance, evolved rapidly through the 1700s and 1800s before it reached close to the design of the modern grand piano. The South Indian veena is still evolving after more than a millennium of development, as are many other modern instruments. However, with the help of advanced engineering techniques, musical instruments have entered a unique period of development (see The new sound of music).
The invention of sound recording in 1877 — the phonograph — started a parallel stream of development in music technology (see graphic). A key milestone was the invention of multitrack recording, which allowed engineers to adjust the tone and volume of each instrument separately. It also enabled them to correct errors for specific instruments, without having to repeat the recording of the entire performance. Current recordings are made on 64 separate tracks. They provide sound engineers with a foundation to enhance the impact of a piece of music according to their skills.
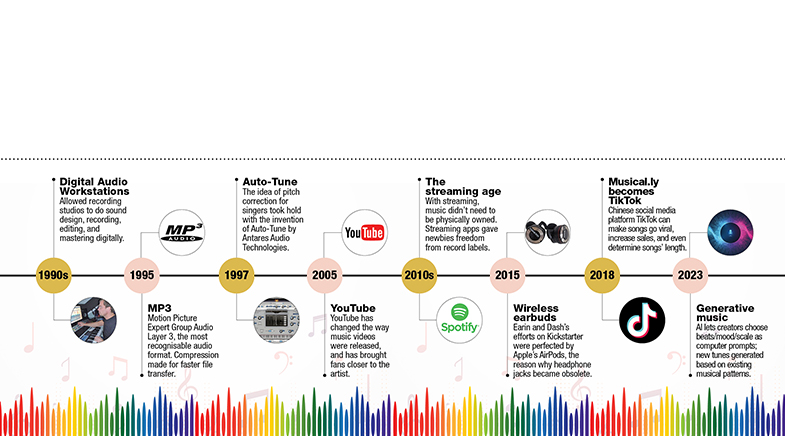
The next big step was in the 1980s when engineers developed digital standards for computers to store music and transfer it to be played on several devices. A computer can play such files on its own, but they sound dull and unmusical, with all notes played at the same level, without a hint of human emotion. Digital recording gave engineers and producers the basic technology to clean up errors and enhance the music. "Audio processing is now more precise than ever," says Sai Shravanam, a music producer in Chennai.
Shravanam set up his recording studio in Chennai in 2007 after quitting his job as Project Associate in the Department of Computer Science & Engineering at IIT Madras. He started playing the tabla at the age of six and continued with his musical education — adding the piano to his repertoire — even as he earned a Master's in Computer Applications. "It is necessary in India to have a post-graduate degree," Shravanam says. "So, I had to do all the mundane things in life." The degree, however, turned out to be useful in his musical career.

He was part of the music industry before he set up his studio — composing music and working with digital studios. He had accompanied the Carnatic singer Bombay Jayashri on the tabla. In 2006, when he was 25 years old, Shravanam produced his album Confluence of Elements, featuring Jayashri. It comprised a set of familiar Carnatic compositions accompanied by the tabla and other instruments, with Shravanam giving his own touch by arranging and mixing the tracks.
As he worked with leading musicians, he learned the elements of studio acoustics and recording technology. He learned to experiment with software as well. "All the tools in the software, the plug-ins, I was learning by myself," he says. "Our basics were strong because we had to find everything ourselves."
In the decade and a half since his studio — called Resound — was set up, recording technology had advanced enough for him to manipulate sound at a high level of precision. Over the decade, multiband compressors, which split sounds into separate frequencies, have improved so much that it is now possible to select and manipulate a single note in a recording. If it sounds louder than it should — when, for instance, the singer moves closer to the mike, even for a second — the volume of that note can easily be reduced. Similarly, smart equalisers can spot and remove accidental vibrations in notes. They can filter the background noise and feeble sounds that leak into the microphone. Smart compressors can use machine learning (ML) to analyse the waveform in real-time and provide the correct setting for a clean voice. "What used to take me 20 minutes now takes two seconds," says Shravanam.
Multiband compressors have improved so much that it is now possible to select and manipulate a single note in recordings.
Plug-ins such as Auto-Tune, which have made pitch correction easy, take singing further into the realm of machines. Backed by a decade of refinement in pitch detection, pitch tracking and formant-shifting algorithms, these help retain the timbre of the voice after correction. Although somewhat controversial due to the reduced demand on singers to learn their craft, pitch correction is a boon to producers as it obviates the need for multiple retakes to correct minor errors. "As producers we are storytellers," says Grammy-award-winning composer and instrumentalist Ricky Kej. "If a take has the right attitude and feel, we don't want to waste that because it is working for our storytelling."
Technology now enables Kej to assess how a composition sounds even before it is recorded. Audio libraries combined with plug-ins – Omnisphere is a popular example – allow him to play instruments digitally before a recording. "Previously, I would write music and listen to it for the first time only when the orchestra played it. But now I can get software to play a mock-up of it and then send that to the instrumentalists, so that they can take it to a whole new level in the recording," Kej says. It reduces the expense of hiring studios. It speeds up work as well.
Much of this work happened in the commercial music industry, but academic researchers are trying to take such technology to the next level. At the Music Informatics Group of the Georgia Institute of Technology, engineers are using the tools of modern computer science and engineering – signal processing, data analysis, ML, and robotics – to enhance the creation and perception of music. Alexander Lerch at the institute uses computers to understand musical content. Gil Weinberg there leads the Robotic Musicianship group, which has created a marimba-playing robotic musician called Shimon; it uses ML for jazz improvisations. Another project of Weinberg's is a prosthetic robotic arm that enables amputees to play drums. Claire Arthur at the institute works on music perception and cognition, computational musicology, and music information retrieval, an area of research in which Chowdhury also works.
PITCH BENDING FOR MICROTONES
The 2003 Tamil film Boys triggered a spark in a college-goer. Krishna Chetan, now a sound engineer working with A.R. Rahman, was captivated by the composer's wildly popular soundtrack that was released just when Indian music was ushering in a new era of digital audio workstations. "I was so taken by the new sound that I wanted to recreate the album on my own. It was the reason I trained myself as a music producer," says Chetan.
During the COVID-19 pandemic, Chetan steered his journey deeper into tech, co-founding Pitch Innovations, a Chennai-based music software company.
During a conversation with keyboardist Karthick Devaraj, Chetan discovered how challenging it was to play Indian gamakas on a Musical Instrument Digital Interface (MIDI) keyboard. This gave Pitch Innovations its first product: pitch bending for microtones in Indian music. Pitch bending enables a smooth transitioning from one chord or note to another on a customisable interface.

Tech-savvy musicians are adapting digital tools to Indian music.
"The MIDI tools available with upcoming composers are mostly developed in the Western world, without any knowledge of the Indian raga system. That is why the music created using those tools sounds quite Western," says Chetan. "We hope our product can help composers create better MIDI mock-ups of Indian melodies."
Lerch, a PhD from the Berlin Institute of Technology, was the co-founder of zplane.development, a music technology company in Berlin, which is now a leading seller of plug-ins for composers. While at zplane, Lerch developed tools for pitch shifting and time stretching, with which one can change the tempo of a song without affecting the pitch.
At Georgia Tech, Lerch's group works on audio content analysis and audio-processing algorithms. For example, engineers can separate the tracks in a stereo recording and enhance the instruments separately, using a technique called stem splitting. Companies such as LALAL.AI, Splitter, Gaudio and AudioShake, all on the western coast of the U.S., sell software for stem splitting. Record companies have been using stem splitting to remaster iconic live concerts and vintage albums. Lerch and other researchers are trying to move beyond such work into the contentious world of generative AI. "I am interested in generative systems, based on text and chat, which are hyped at the moment," says Lerch. "The focus should be on how we can create something that we can control." For example, can producers prompt computers to make a piece rhythmically a bit denser? Can they ask it to extend the melodic range?
This leads scientists to a related question: can computers understand music from a human point of view?

PARSING MUSIC
After Chowdhury joined Widmer's group, he set out to identify key components that dictate the mood of a piece.
This wasn't an easy exercise for a machine. A sonata, for example, is a complex work of art that provides significant freedom for pianists to provide their own interpretations. It is not just enough to analyse the tempo and tone of a piece. Analysis requires a level of detail that cannot be obtained from existing recordings. For this, pianists must play using a special computer grand piano that can record each note in high precision. So, the recordings of the great pianists were of no use to Widmer. Then he stumbled upon a computer-controlled piano recording of Russian pianist Nikita Magaloff. In 1989, Magaloff had performed on such a piano the entire works of Frédéric Chopin, which gave Widmer access to roughly 300,000 emotionally charged notes. Their computer analyses (bit.ly/magaloff-music) gave the research group information about how humans perceive sound and emotion. Their computer now plays Chopin with emotion, often fooling experienced listeners about the identity of the player.
Chowdhury, on the other hand, used human judgement to identify emotional elements. He chose seven features to describe musical emotion and trained an ML model to identify them. These features were melodiousness, articulation, rhythmic stability, rhythmic complexity, dissonance, tonal stability, and the key of the piece. A piece that was articulated more, sounded more staccato. Rhythmic complexity was determined by the number of layers of rhythm a piece had. The key of the work, depending on whether it was major or minor, determined the mood of the entire composition.
Instead of having people label songs based on emotions, Chowdhury had a set of volunteers sort out the songs according to these seven features. Their choices were then fed into the ML model to allow it to make correlations. The emotions were represented in a two-dimensional plane. The y-axis represented the arousal, how intensely an emotion was perceived. The x-axis represented the valence, which rated the positivity or negativity of the emotion. To remove biases, the training audio was taken from an open dataset where any musician could submit samples and avoided popular pieces to which different people may have had different reactions.
The aim is not to get computers to create compositions; it is to get them to assist humans in creating what they want.
The audio clips were first pre-processed into spectrograms, which are two-dimensional (time vs frequency) representations of audio. "You can visually see how a song looks in the frequency-time plane. Which is why machine learning architectures originally designed for analysing images can also be made to work for audio," says Chowdhury. The model that he trained was a deep neural network model broken into two parts. The first part takes in audio data in the form of spectrograms and outputs these seven perceptual features. The second part of the model then maps these seven perceptual features to emotion predictions.
Such work is part of the growing field of music informatics, an area of research that gets computers to listen to music and then build systems that can create music. Since computers have no human experience or emotions to express, the aim of such work is not to get computers to create entire compositions on their own. It is to get them to assist humans in creating precisely what they want — such as producing better results for a prompt (a search query) – or getting composers to understand how a piece can sound before they finish composing it. As a bonus, such tools can help amateurs or even untrained people to write music.
Two recent start-ups – Beatoven in Bengaluru, and Musicfy in Delaware in the U.S. – allow users untrained in music to create their own music through prompts. Such music is now used as a background score for videos, podcasts, and audiobooks. In their prompts, users of the software can specify parameters such as mood, genre, tempo, and duration. Using Musicfy, which takes audio inputs, a user can hum a song, choose an instrument, and then let its AI platform generate a piece of music. A third company, Singapore-based BandLab, can create a song based on lyrics. "I see these apps more as tools to solve creative blocks," says Mansoor Rahimat Khan, co-founder of Beatoven. "You get an idea and you start building on top of it. You are not going to make hit songs just using AI."

SOUND, FROM ALL AROUND
The full effect of microscopic audio editing will only be felt by the connoisseur if the listening equipment is technologically sound. The emerging field of spatial audio allows sound to be more immersive using ML models to figure out which direction the sound must be sent out to.
"When sound travels to our ears, the unique characteristics of your head — its physical shape, the shape of your outer and inner ears, even the shape of your nasal cavities — change the audio spectrum of the original sound," Qi ‘Peter' Li, founder of Li Creative Technologies, explains in a paper (bit.ly/ ieee-audio).
Since 2021, Apple Music has been working on providing personalised spatial audio, releasing Atmos on AirPods, and then adding personalised spatial profiles and head-tracking features based on face scans done by the iPhone. This placed the listener in a theatre-like surround sound environment, where, if the sound came from the right side of the screen and the listener turned to the right, the sound would appear to come from the front.

ML has allowed sound to become an immersive experience.
Its latest offering, Vision Pro, scans the room the listener is in to learn the geometry of the walls, the material covering it, and so on. It then simulates the sound propagation to appear as if it is coming from the room itself, providing a 3D experience. The ultimate aim for researchers is to recreate the feel of a live music performance.
WHOSE VOICE IS IT ANYWAY?
Sound engineer Krishna Chetan recently received an urgent call from a friend, an upcoming music composer, asking whether he could help recreate singer Kailash Kher's voice. Chetan had already done something similar for composer A.R. Rahman, with whom he has been working for two decades. The duo had brought back the voices of two late singers, Bamba Bakya and Shahul Hameed, with the consent of their families, for the Tamil film Lal Salaam.
"The budget for the film of my friend is small, and they can't afford to onboard a big singer and then decide it is not working for them. He was convinced that Kailash Kher could take the song to another level, and he needed to generate his voice in the mock-up of the song, just to get the producer's approval," Chetan says.
It is a situation Chetan himself, and countless others, have faced before: they want to check whether a specific singer's voice and style are suitable for a song. When composers want to create a mock-up of a song in a particular singer's voice, they have a pilot singer first sing the song, and then re-synthesise the song in the voice of the desired performer, using the Retrieval-based-Voice-Conversion (RVC) algorithm. "Even the expressions and the attitude in a singer's voice are essentially results of pitch and volume variation, so they too can be recreated," he says.

Chetan compares this to the development of cloud-based audio libraries seven years ago. "People might not be that open to it today," he concedes, "But I think it will be a big leverage for singers. If you have a unique voice, you can be in 100 studios at once."
It has perhaps been the aim of most tech development since the noughties: being everywhere, doing everything, all at once.
See also:










2D or not 2D...
...that is no question. Roll over, silicon.

The 'Seagull' who soared to space
Sixty years ago, Valentina Tereshkova became an unlikely symbol of Soviet space ascendance.

Quantum riddles
The physics is puzzling, but some enduring mysteries of quantum mechanics may be a bit closer to being solved.

Have a
story idea?
Tell us.
Do you have a recent research paper or an idea for a science/technology-themed article that you'd like to tell us about?
GET IN TOUCH